
The coaching of Giant Language Fashions (LLMs) like GPT-3 and Llama on a big scale faces vital inefficiencies attributable to {hardware} failures and community congestion. These points result in substantial GPU useful resource waste and prolonged coaching durations. Particularly, {hardware} malfunctions trigger interruptions in coaching, and community congestions pressure GPUs to attend for parameter synchronization, additional delaying the coaching course of. Addressing these challenges is essential for advancing AI analysis, because it straight impacts the effectivity and feasibility of coaching extremely advanced fashions.
Present strategies to sort out these challenges contain primary fault tolerance and site visitors administration methods. These embrace utilizing redundant computations, erasure coding for storage reliability, and multi-path methods to deal with community anomalies. Nevertheless, these strategies have vital limitations. They don’t seem to be environment friendly in real-time functions attributable to their computational complexity and intensive guide intervention necessities for fault prognosis and isolation. Moreover, these strategies typically fail to handle community site visitors successfully in shared bodily clusters, resulting in congestion and lowered efficiency scalability.
The researchers From the Alibaba group suggest a novel strategy named C4 (Calibrating Collective Communication over Converged Ethernet), designed to handle the inefficiencies of present strategies by specializing in enhancing communication effectivity and fault tolerance in large-scale AI clusters. C4 consists of two subsystems: C4D (C4 Prognosis) and C4P (C4 Efficiency). C4D improves coaching stability by detecting system errors in actual time, isolating defective nodes, and facilitating fast restarts from the final checkpoint. C4P optimizes communication efficiency by effectively managing community site visitors, thereby decreasing congestion and enhancing GPU utilization. This strategy represents a major contribution to the sector by providing a extra environment friendly and correct answer in comparison with present strategies.
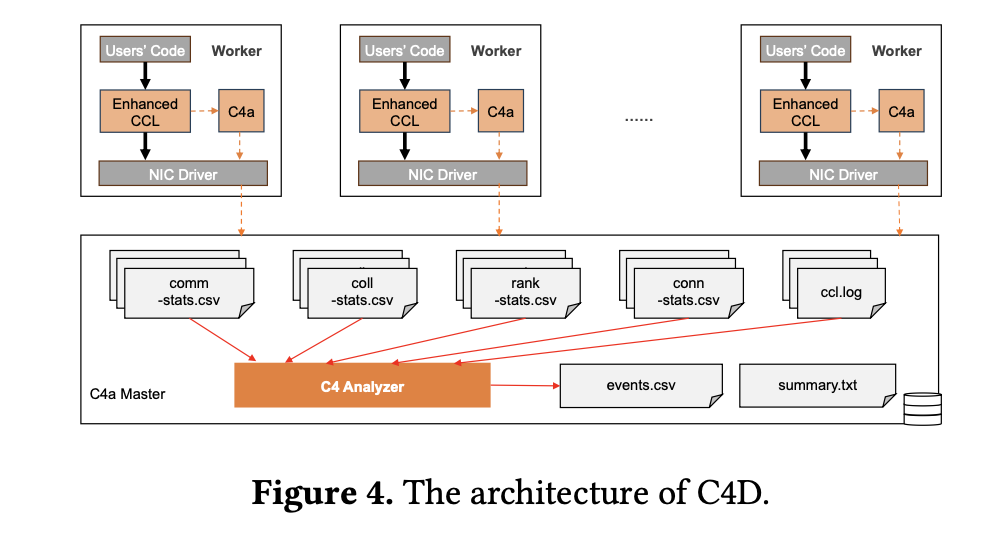
The C4 system leverages the predictable communication patterns of collective operations in parallel coaching to implement its options. C4D enhances the collective communication library to observe operations and detect potential errors primarily based on anomalies within the homogeneous traits of collective communication. As soon as a suspect node is recognized, it’s remoted and the duty is restarted, minimizing downtime. C4P employs site visitors engineering strategies to optimize the distribution of community site visitors, balancing the load throughout a number of paths and dynamically adjusting to community adjustments. The system’s deployment throughout large-scale AI coaching clusters has proven to chop error-induced overhead by roughly 30% and improve runtime efficiency by about 15%.
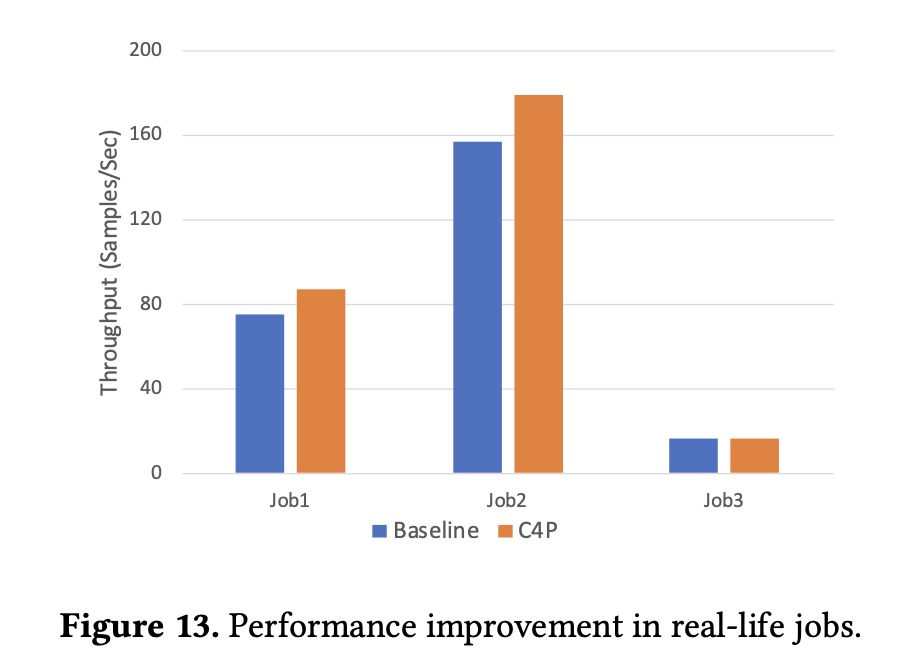
The researchers evaluated the effectiveness of C4 by specializing in key efficiency metrics comparable to throughput and error discount. For example, the determine under from the paper highlights the efficiency enchancment throughout three consultant coaching jobs, exhibiting that C4P will increase throughput by as much as 15.95% for duties with excessive communication overhead. The desk compares completely different strategies, together with the proposed C4 strategy, with present baselines, highlighting the numerous enchancment in effectivity and error dealing with.
In conclusion, the proposed strategies present a complete answer to the inefficiencies in large-scale AI mannequin coaching. The C4 system, with its subsystems C4D and C4P, addresses essential challenges in fault detection and community congestion, providing a extra environment friendly and correct methodology for coaching LLMs. By considerably decreasing error-induced overhead and enhancing runtime efficiency, these strategies advance the sector of AI analysis, making high-performance mannequin coaching extra sensible and cost-effective.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 44k+ ML SubReddit
![]()
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.




















{kind=link}