
In case you’ve been following our articles on Massive Language Fashions (LLMs) or digging into AI, you’ve most likely come throughout the time period token quite a lot of instances. However what precisely is a “token,” and why does everybody hold speaking about it?
It is a kind of buzzwords that will get thrown round lots, but few individuals cease to elucidate it in a method that’s really comprehensible.
And right here’s the catch – with out a strong grasp of what tokens are, you’re lacking a key piece of how these fashions perform.
Actually, tokens are on the core of how LLMs course of and generate textual content. In case you’ve ever puzzled why an AI appears to stumble over sure phrases or phrases, tokenization is commonly the offender.
So, let’s lower by the jargon and discover why tokens are so important to how LLMs function.
What are tokens?
A token in Massive Language Fashions is principally a piece of textual content that the mannequin reads and understands.
It may be as quick as a single letter or so long as a phrase and even a part of a phrase. Consider it because the unit of language that an AI mannequin makes use of to course of data.
As a substitute of studying complete sentences in a single go, it breaks them down into these little digestible items – tokens.
In easier phrases:
Think about you are attempting to show a baby a brand new language. You’d begin with the fundamentals: letters, phrases, and easy sentences.
Language fashions work in the same method. They break down textual content into smaller, manageable items referred to as tokens.
💡
For instance, the sentence “The short brown fox jumps over the lazy canine” could possibly be tokenized as follows:
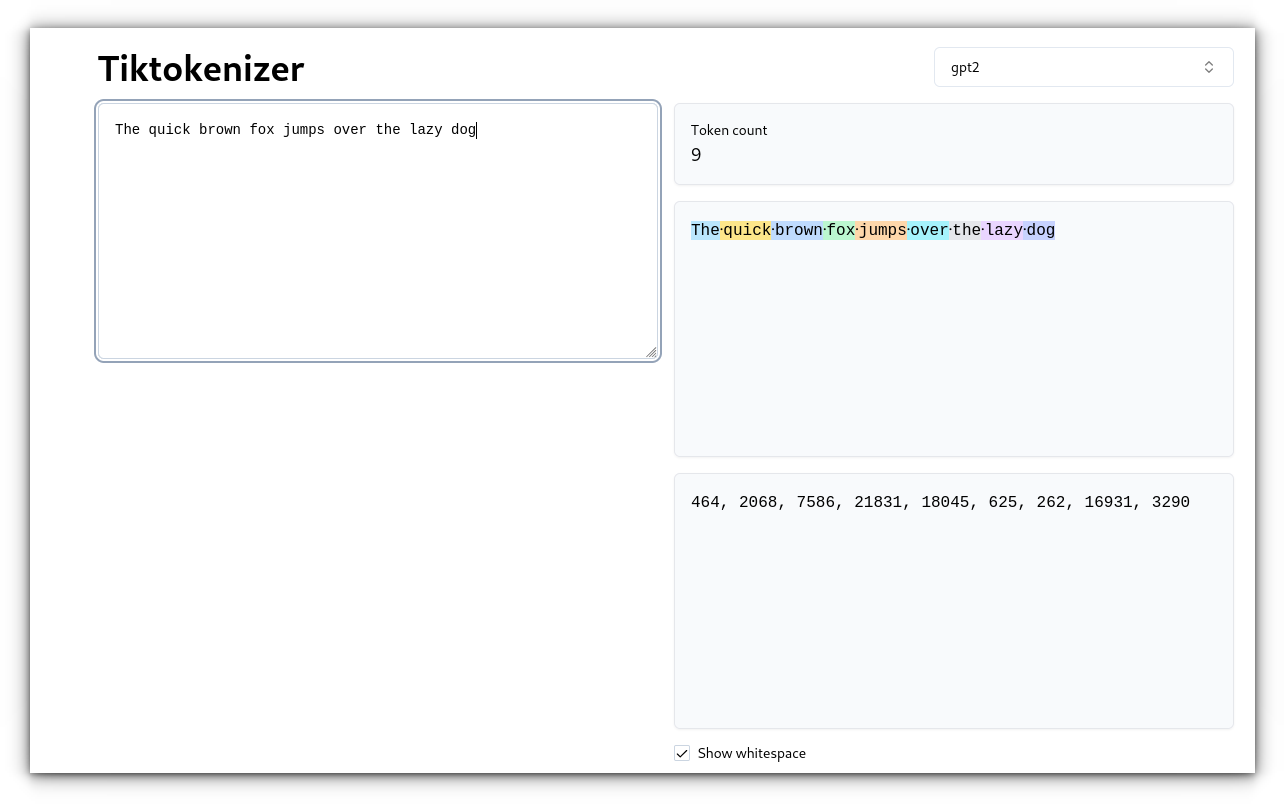
How do language fashions use tokens?
As soon as a textual content is tokenized, a language mannequin can analyze every token to know its that means and context. This permits the mannequin to:
Perceive the that means: The mannequin can acknowledge patterns and relationships between tokens, serving to it perceive the general that means of a textual content.Generate textual content: By analyzing the tokens and their relationships, the mannequin can generate new textual content, reminiscent of finishing a sentence, writing a paragraph, and even composing a complete article.
Tokenization Strategies
Once we discuss tokenization within the context of Massive Language Fashions (LLMs), it is essential to know that completely different strategies are used to separate textual content into tokens. Let’s stroll by the commonest approaches used immediately:
1. Phrase-Stage Tokenization
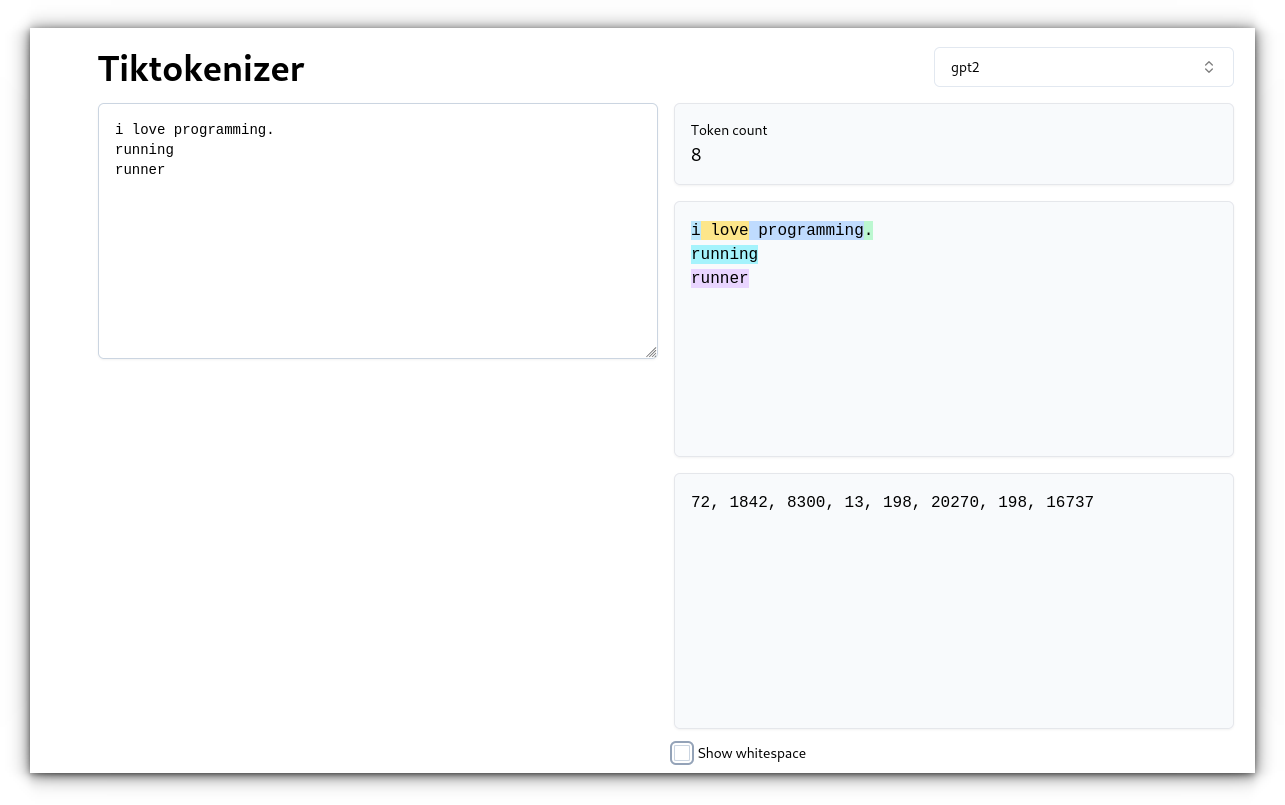
That is the only method the place the textual content is cut up by areas and punctuation. Every phrase turns into its personal token.
Instance: Unique textual content: “I really like programming.” Tokens: [“I”, “love”, “programming”, “.”]
Whereas that is easy, it may be inefficient.
For instance, “working” and “runner” are handled as separate tokens regardless that they share a root.
2. Subword-Stage Tokenization
Subword tokenization breaks phrases into smaller, significant items, which makes it extra environment friendly.
It’s nice for dealing with phrases with frequent prefixes or suffixes and might cut up uncommon or misspelled phrases into recognized subwords.
Two well-liked algorithms are Byte Pair Encoding (BPE) and WordPiece.
Instance (with BPE): Unique textual content: “underestimate” Tokens: [“und”,”erest”, “imate”] and few others:
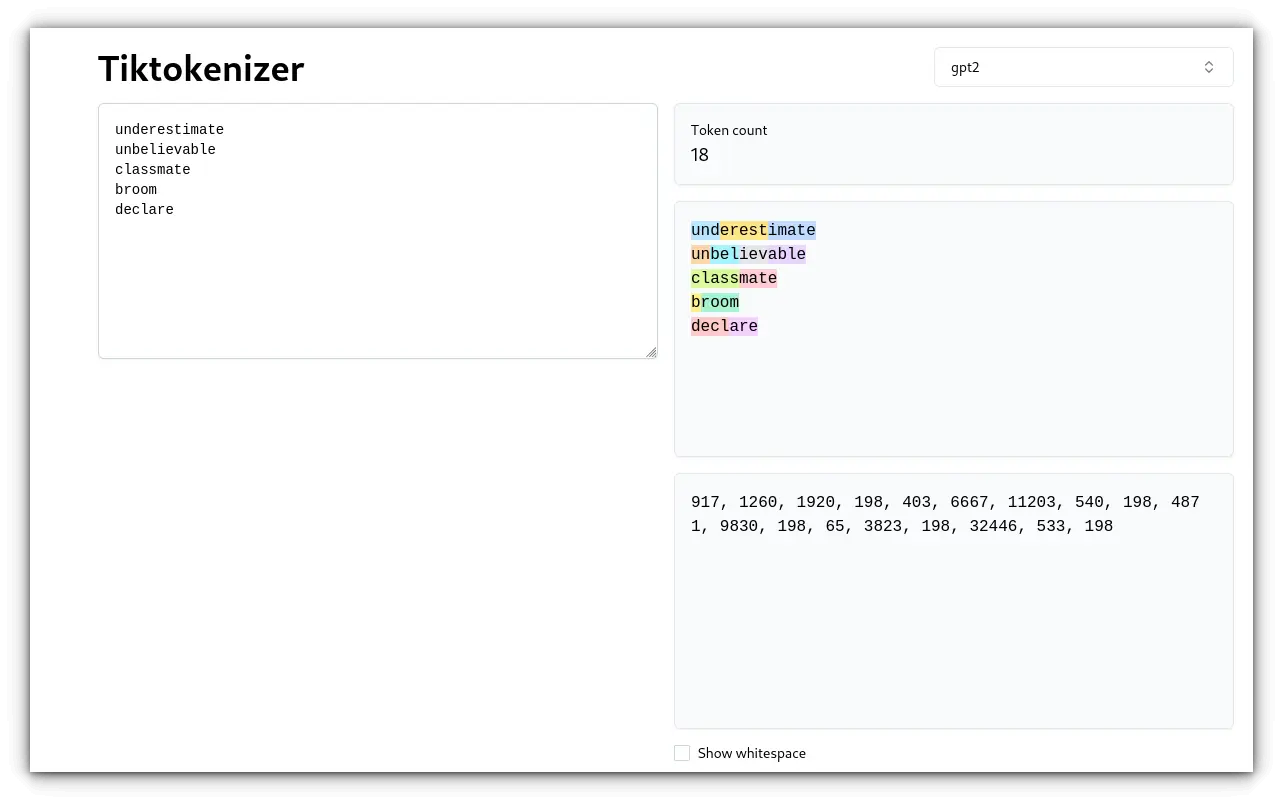
On this case, BPE breaks down “underestimate” into smaller items that can be utilized in different phrases, making it simpler to deal with variations and misspellings.
3. Character-Stage Tokenization
This methodology splits textual content into particular person characters.
It’s very versatile and might deal with any textual content, together with non-standard or misspelled phrases.
Nevertheless, it may be much less environment friendly for longer texts as a result of the mannequin offers with many extra tokens.
Instance: Unique textual content: “cat” Tokens: [“c”, “a”, “t”]
Character-level tokenization is beneficial for excessive flexibility however usually ends in extra tokens, which could be computationally heavier.
4. Byte-Stage Tokenization
Byte-level tokenization splits textual content into bytes quite than characters or phrases.
This methodology is very helpful for multilingual texts and languages that don’t use the Latin alphabet, like Chinese language or Arabic.
It’s additionally essential for circumstances the place the precise illustration of the textual content is essential.
Token Restrict
A token restrict refers back to the most variety of tokens an LLM can course of in a single enter, together with each the enter textual content and the generated output.
Consider it as a buffer—there’s solely a lot knowledge the mannequin can maintain and course of directly. If you exceed this restrict, the mannequin will both cease processing or truncate the enter.
For instance, GPT-3 can deal with as much as 4096 tokens, whereas GPT-4 can course of as much as 8192 and even 32,768 tokens, relying on the model.
Which means every thing within the interplay, from the immediate you ship to the mannequin’s response, should match inside that restrict.
Why Do Token Limits Matter?
Contextual Understanding: LLMs depend on earlier tokens to generate contextually correct and coherent responses. If the mannequin reaches its token restrict, it loses the context past that time, which may end up in much less coherent or incomplete outputs.Enter Truncation: In case your enter exceeds the token restrict, the mannequin will lower off a part of the enter, usually ranging from the start or finish. This may result in a lack of essential data and have an effect on the standard of the response.Output Limitation: In case your enter makes use of up many of the token restrict, the mannequin may have fewer tokens left to generate a response. For instance, if you happen to ship a immediate that consumes 3900 tokens in GPT-3, the mannequin solely has 196 tokens left to offer a response, which could not be sufficient for extra advanced queries.
Conclusion
Tokens are important for understanding how LLMs perform.
Whereas it could appear trivial at first, tokens affect every thing from how effectively a mannequin processes language to its general efficiency in several duties and languages.
Personally, I imagine there’s room for enchancment. LLMs nonetheless battle with nuances in non-English languages or code, and tokenization performs an enormous half in that.
I’d love to listen to your ideas – drop a remark beneath and let me know the way you suppose developments in tokenization may have an effect on language fashions’ potential to deal with advanced or multilingual textual content!





















{kind=link}